DB 최적화

하는 방법은 여러 가지이지만, 스케일업, 캐싱, sql튜닝, 샤딩 등등이 있고 sql 최적화가 가장 금전적, 시간적 비용이 적다. 시스템 변경 없이 성능 개선이 가능하다.
where 조건1 and 조건2 에서 둘 중에 유니크한 값이 있으면 그걸 create index하는게 훨씬 빠르다.
sql 쿼리 자체가 비효율적으로 짜있으면 다른 성능 개선법을 쓰더라도 효과가 극적이지 않다.
💡+근본적인 문제를 해결하는 방법이 sql 튜닝일 가능성이 높다.
예를 들어 user table 에 id auto_increment, name, age 가 있을 때,
create index age로 인덱스를 생성하면 내부적으로 age를 기반으로 한 오름차순된 표가 생성된다.
select * from users where age = 23;일 때 정렬되지 않은 age에서 23을 찾기 위한 시간이 대폭 단축된다.
unique 속성을 넣으면 자동으로 인덱스 지표가 된다. pk도 자동 인덱스로 된다.(클러스터링 인덱스)
💡unique 속성을 넣으면 인덱스가 생성되기 때문에 조회 성능이 향상된다.
그럼 index는 만능이냐? 아니다
데이터가 추가 될 때, index가 많아질 수록 원래 테이블과 인덱스용 테이블에 데이터를 넣어야하기 때문에 성능은 느려질 수 밖에 없다.
💡즉, 조회성능은 올라가지만, 쓰기 작업(삽입, 수정, 삭제)이 느려진다.
그러므로, 인덱스는 최소한만 만들고 사용한다.
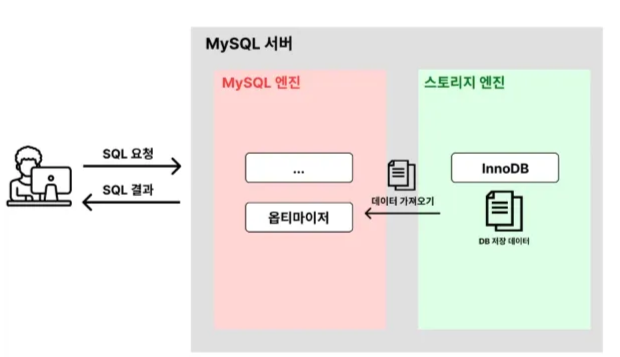
실행 계획 이란?
옵티마이저가 SQL문을 어떤 방식으로 어떻게 처리할 지를 계획. 이 실행 계획을 보고 비효율적으로 처리하는 방식이 있는지 점검하고, 비효율적인 부분이 있다면 더 효율적인 방법으로 SQL문을 실행하게끔 하는 것이 목표
확인 방법
#실행 계획 조회하기
EXPLAIN [SQL문]
#실행 계획에 대한 자세한 정보 조회하기
EXPLAIN ANALYZE [SQL문]

EXPLAIN 실행하면 나오는 테이블 종류이다.
TYPE은 테이블에 있는 데이터를 어떤 방식으로 조회를 했는지
POSSIBLE-KEYS는 사용할 수 있는 인덱스 목록
KEY는 데이터 조회 시 실제 사용한 인덱스 값
REF는 조인하는 상황에서 어떤 값을 기준으로 데이터를 JOIN했는지
ROWS 는 SQL문 수행을 위해 테이블에 접근한 데이터의 개수(액세스 수)많으면 많을 수록 오래 걸린다.(이걸 줄이는게 튜닝 핵심)
FILTER는 필터 조건으로 어느 정도의 비율로 데이터를 제거했는지 (WHERE)등
예를 들어 값이 30이면 100개의 데이터를 불러와서 70개는 갔다 버리고 30개만 가져다 응답을 했다는것
낮으면 낮을 수록 쓸데 없는 데이터를 많이 가져왔다는 지표이다.
ANALYZE

ANALYZE하면 나오는 정보
! 더 깊은 층부터 보자 filter 말고 table 먼저 보기
(COST, ROW는 보지말고) 그다음 ACTUAL TIME이 중요
( 숫자..숫자 rows, loops) 각자
처음 숫자는 첫 데이터를 조회하기까지 걸린시간, 풀테이블 스캔에 걸린시간 0.0673ms
rows는 이작업을 할 때 접근한 데이터의 수
조건에 맞는 데이터를 선별
실제 걸린시간 0.0748 - 0.0673 = 0.01ms 가 걸렸다고 볼 수 있다.
필터링하는데 얼마 안결렸다는 소리
type 칼럼 다시 보기
ALL : 풀 테이블 스캔
인덱스를 활용하지 않고 테이블을 처음부터 끝까지 전부 뒤져본 것이다.
index : 풀 인덱스 스캔
인덱스 테이블을 처음부터 끝까지 다 뒤져서 데이터를 찾는 방식. 인덱스의 테이블은 실제 테이블보다 작다. 풀 테이블 스캔보다 효율적. 하지만 인덱스 테이블 전체를 읽어야하기에 아주 효율적이라고 볼 수는 없다.
예를 들어 백만개의 더미 데이터를 만들고
CREATE INDEX idx_name ON users (name);
SELECT * FROM users
ORDER BY name
LIMIT 10;
입력하면 explain type 칼럼은 index를 나타낸다.
name을 기준으로 정렬해서 데이터를 가져와야 하므로, name을 기준으로 정렬되어 있는 ‘인덱스’를 조회한다. 이 인덱스를 모두 불러온 뒤 최상단 10개만 뽑아 낸다.
const : 1건의 데이터를 바로 찾을 수 있는 경우
아주 효율적인 방식 왜 가능한가
- 인덱스가 없다면 특정 값을 일일이 다 뒤져야 한다. 그래서 1건의 데이터를 바로 찾을 수 없다.
- 인덱스가 있는데 고유하지 않다면 (NOT UNIQUE) 원하는 1건의 데이터를 찾았다고 하더라도, 나머지 데이터에 같은 값이 있을 지도 모르므로 다른 데이터들도 체크해봐야 한다.
- 고유하다면(unique) 1건의 데이터를 찾는 순간, 나머지 데이터는 아예 볼 필요가 없어진다. 왜냐하면 찾고자 하는 데이터가 유일한 데이터이기 때문이다.
고유 인덱스와 기본 키는 전부 unique한 특성을 가지고 있다.
const는 더 이상의 성능 개선이 필요 없을 정도로 빠르다.
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
account VARCHAR(100) UNIQUE
);
INSERT INTO users (account) VALUES
('user1@example.com'),
('user2@example.com'),
('user3@example.com');
EXPLAIN SELECT * FROM users WHERE id = 3;
EXPLAIN SELECT * FROM users WHERE account = 'user3@example.com';
밑에 실행문 두 가지 모두 type 칼럼은 const가 나온다. 왜? unique하기 때문이다.
range : 인덱스 레인지 스캔
인덱스 레인지 스캔은 인덱스를 활용해 범위 형태의 데이터를 조회한 경우를 뜻한다. 범위 형태란 between, 부등호(<. >, ≥, ≤), IN, LIKE를 활용한 데이터 조회를 뜻한다.
이 방식은 인덱스를 활용하기 때문에 효율적인 방식이다. 하지만 인덱스를 사용하더라도 데이터를 조회하는 범위가 클 경우 성능 저하의 원인이 되기도 한다.

EXPLAIN SELECT * FROM users
WHERE age BETWEEN 10 and 20;
EXPLAIN SELECT * FROM users
WHERE age IN (10, 20, 30);
EXPLAIN SELECT * FROM users
WHERE age < 20;
모두 type = range이다. (age를 인덱스로 추가한 경우)
ref : 비고유 인덱스를 활용하는 경우
비고유 인덱스를 사용하는 경우 (=unique가 아닌 컬럼의 인덱스를 사용한 경우) type에 ref가 출력된다.
값을 찾았다고 하더라도 그 값만 있는게 아닐 수 있기 때문에 찾아야함

CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
);
INSERT INTO users(name) VALUES ('박재성'),('김지현'), ('이지훈');
CREATE INDEX idx_name ON users(name);
EXPLAIN SELECT * FROM users WHERE name = '박재성';
만약 unique인 값을 index로 했다면, const임 그러나 아니므로 ref
한 번에 너무 많은 데이터를 조회하는 sql문 튜닝하기
DROP TABLE IF EXISTS users;
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT
);
INSERT INTO users (name, age)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터 수
)
SELECT
CONCAT('User', LPAD(n, 7, '0')), -- 'User' 다음에 7자리 숫자로 구성된 이름 생성
FLOOR(1+RAND() * 1000) AS age -- 1부터 1000사이의 난수로 나이 생성
FROM cte;
SELECT * FROM users LIMIT 10000;
안 되면 자체 리밋을 풀어야 한다.
위의 경우 평균 200ms 걸린다.
10개 limit으로 검색하면 약 20ms
내가 생각했던 방법 selectAll() {모든 영상 불러오기 임)을 그대로 select * from video를 하면 너무 많은 데이터를 가져오기 때문에 처음 보이는 페이지 ex) 5개를 먼저 로딩(또는 캐싱)하고,
💡 데이터를 조회할 때 한 번에 너무 많은 데이터를 조회하는 건 아닌 지 체크해보기
LIMIT, WHERE 문 등을 활용해서 한 번에 조회하는 데이터의 수를 줄이는 방법 고민
where 문 튜닝하기 1
최근 3일 이내에 가입한 유저 조회하기
DROP TABLE IF EXISTS users;
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
department VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO users(name, department, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User'다음에 7자리 숫자로 구성된 이름 생성
CASE
WHEN n % 10 = 1 THEN 'Engineering'
WHEN n % 10 = 2 THEN 'Marketing'
WHEN n % 10 = 3 THEN 'Sales'
WHEN n % 10 = 4 THEN 'Finance'
WHEN n % 10 = 5 THEN 'HR'
WHEN n % 10 = 6 THEN 'Operation'
WHEN n % 10 = 7 THEN 'IT'
WHEN n % 10 = 8 THEN 'Customer Service'
WHEN n % 10 = 9 THEN 'Research and Development'
ELSE 'Product Management'
END AS department,-- 의미 있는 단어 조합으로 부서 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() *3650) DAY)+
INTERVAL FLOOR(RAND() *86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
-- 잘 생성되었나 확인
SELECT COUNT(*) FROM users;
SELECT * FROM users LIMIT 10;
-- 테스트
SELECT * FROM users
WHERE created_at >=DATE_SUB(NOW(), INTERVAL 3 DAY);
-- 이거 실행하면 약 250ms 걸림 type 은 all 즉, 비효율적 row수는 996810이 나온다.
CREATE INDEX idx_created_at ON users (created_at);
SHOW INDEX FROM users; -- 생성되었나 확인
-- 이후 똑같은 쿼리로 조회해보면 약 55ms 가 나온다.
type 도 range로 바뀐다. row수는 1147
where 문 튜닝하기 2
sales 부서이면서 최근 3일 이내에 가입한 유저 조회하기
DROP TABLE IF EXISTS users;
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
department VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
INSERT INTO users(name, department, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000
)
SELECT
CONCAT('User', LPAD(n, 7, '0')) AS name, -- 'User'다음에 7자리 숫자로 구성된 이름 생성
CASE
WHEN n % 10 = 1 THEN 'Engineering'
WHEN n % 10 = 2 THEN 'Marketing'
WHEN n % 10 = 3 THEN 'Sales'
WHEN n % 10 = 4 THEN 'Finance'
WHEN n % 10 = 5 THEN 'HR'
WHEN n % 10 = 6 THEN 'Operation'
WHEN n % 10 = 7 THEN 'IT'
WHEN n % 10 = 8 THEN 'Customer Service'
WHEN n % 10 = 9 THEN 'Research and Development'
ELSE 'Product Management'
END AS department,-- 의미 있는 단어 조합으로 부서 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() *3650) DAY)+
INTERVAL FLOOR(RAND() *86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
-- 잘 생성되었나 확인
SELECT COUNT(*) FROM users;
SELECT * FROM users LIMIT 10;
-- 테스트할 쿼리
SELECT * FROM users
WHERE department = 'Sales'
AND created_at >= DATE_SUB(NOW(), INTERVAL 3 DAY)
-- 소요시간 약 200ms
-- type 도 all, row 도 996810임
-- explain analyze해보면 full table scan했고 152ms걸렸고 탐색 행한 수가 1e + 6 1e가 10이므로 10의
-- 6제곱 만큼 약(100만)
-- filtering 보면 204ms 라고 나옴 이 차이인 52ms만큼 필터링하는데 걸린 시간
-- 성능개선 어떻게?
-- department랑 created_at이랑 어떤걸 인덱스로 하지? (둘 다도 가능) 판단이 필요함
-- created_At으로 인덱스 만들면 약 30ms로 많이 향상 되었다.
-- type은 range, row = 1079가 나온다.
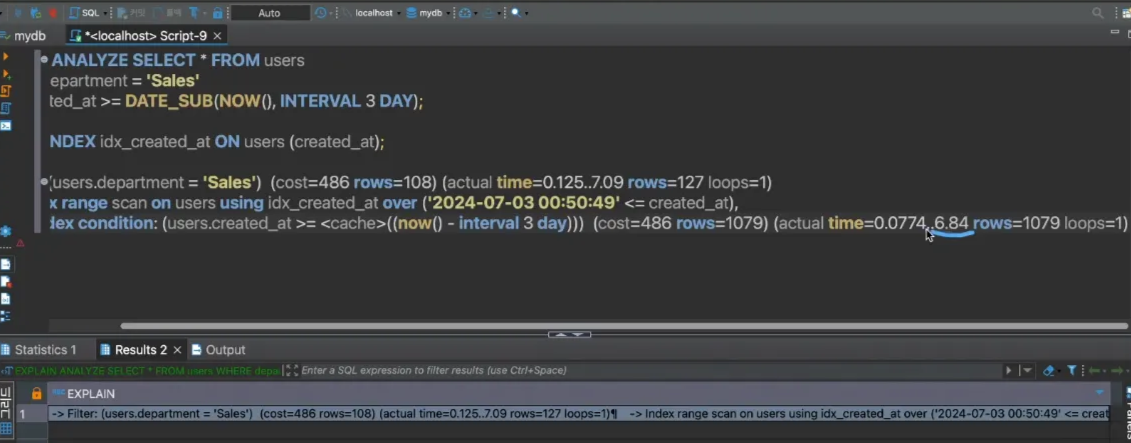
인덱스 레인지로 검색하여 날짜를 만족하는 사람을 가져올 때 6.84ms가 걸린것이다. row수 1079개
그 이후, 필터를 거친다. sales가 부서인 사람 가져오는데 7.09ms - 6.84ms = 0.25ms 걸림
⇒ 결론 속도 엄청 빨라졌다.
💡그렇다면, department를 index로 한다면?
약 130ms 가 나온다. (성능이 덜 향상 되었다) 왜?
explain 해보면 type이 ref로 나온다. 즉, department는 고유한 값이 아님. row는 약 19만개
explain analyze하면 먼저 부서가 sales인 사람 먼저 찾고 100ms라고 나온다.
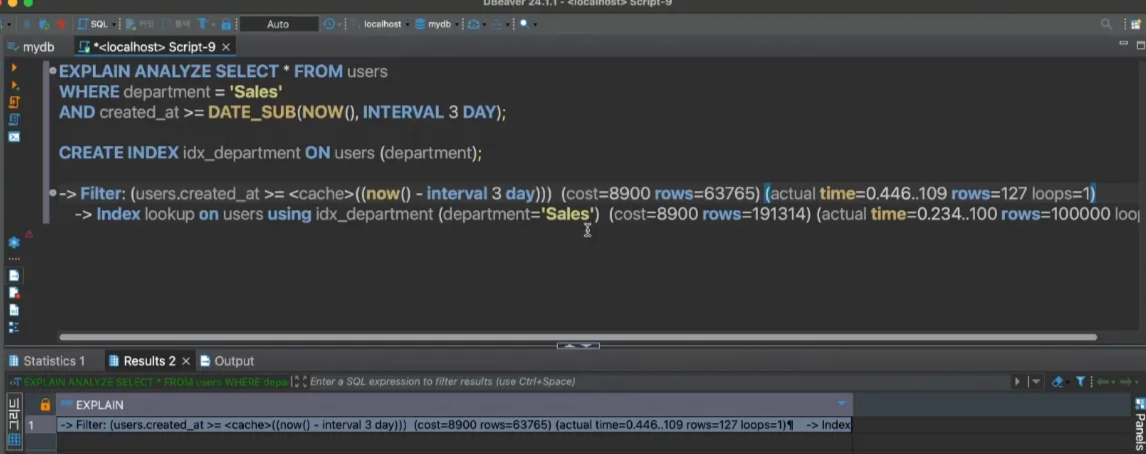
그러면 created_at 도 범위가 아니라 =3 으로 정확한 값을 찾으면 ref가 나오나??
💡그러면 둘 다 인덱스로 등록하면?
약 30ms로 created_at 을 인덱스로 등록한것 만큼 효과적으로 되었다.
explain 을 보면 type은 range possible keys 는 둘 다 있지만 실제 사용 key는 created_At만 사용했다.
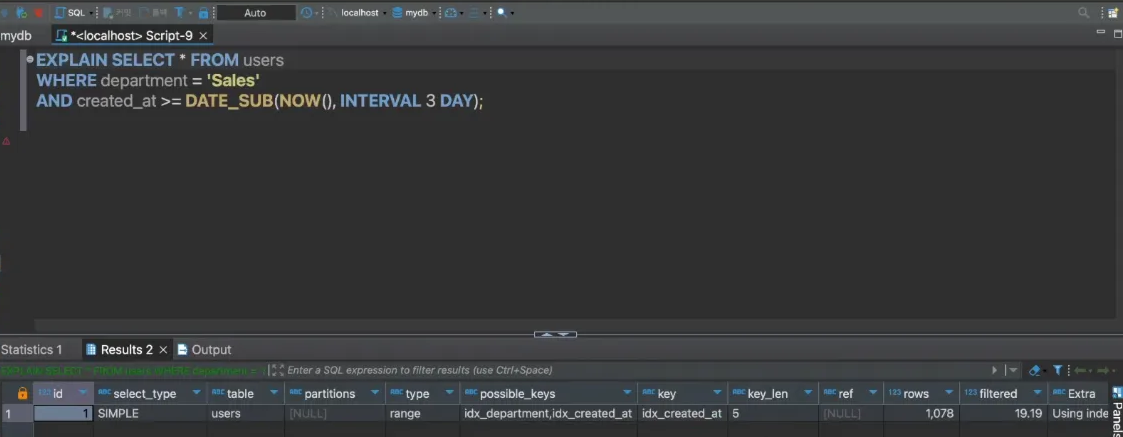
왜??
optimizer가 두 가지 인덱스를 비교해보니 created_at 쓰는게 효율적일 거라고 판단한것.
결론 : created_at만을 인덱스로 만드는 것이 효율적이다.
이것저것 추가하면 쓰기 작업이 느려짐
💡데이터 액세스(rows)를 크게 줄일 수 있는 컬럼은 중복 정도가 낮은 컬럼이다. 따라서 중복 정도가 낮은 컬럼을 골라서 인덱스를 생성하는게 좋다. (절대적인거 아님)
멀티컬럼인덱스 방식도 있다.
ALTER TABLE users DROP INDEX idx_created_at_department;
CREATE INDEX idx_department_created_at ON users (created_at, department);
20ms 소요 type range rows = 1077개
()안에 순서를 바꿔봐도 이전 멀티컬럼 인덱스와 성능이 비슷하다.
이렇게 단일컬럼 인덱스와 차이가 별로 없으면 단일컬럼 인덱스를 거는게 좋다. (인덱스는 최소화가 좋으므로)
💡멀티컬럼 인덱스의 퍼포먼스가 단일컬럼 인덱스와 차이가 별로 없으면 일반 인덱스를 사용하자(인덱스는 최소화가 좋으므로)
SQL 성능 튜닝에서 WHERE 절에서 인덱스를 활용하는 것 외에도 알아야 할 중요한 최적화 기술이 여러 가지 있습니다. 인덱스 활용은 중요한 요소지만, 효율적인 데이터베이스 튜닝을 위해서는 다른 다양한 최적화 요소들도 고려해야 합니다. 아래는 추가적으로 알아야 할 주요 성능 튜닝 방법들입니다:
1. 인덱스의 종류와 설계
- 단일 인덱스 vs. 복합 인덱스: 여러 열에 대한 조건을 자주 사용할 경우, 복합 인덱스(다중 열 인덱스)를 생성하면 성능을 크게 개선할 수 있습니다. 단, 복합 인덱스에서 중요한 것은 인덱스의 열 순서입니다. 일반적으로 WHERE 조건에서 자주 사용되는 열과 선택도가 높은 열을 우선적으로 배치합니다.
- 클러스터드 인덱스 vs. 비클러스터드 인덱스: 클러스터드 인덱스는 테이블의 물리적 순서를 결정하므로 성능에 큰 영향을 미칩니다. PK(Primary Key)에 클러스터드 인덱스가 기본 설정되지만, 필요에 따라 변경할 수 있습니다.
2. 쿼리 재작성
- 서브쿼리 vs. 조인: 종종 서브쿼리보다 조인이 더 효율적일 수 있습니다. MySQL에서는 조인이 서브쿼리보다 더 빠르게 실행되는 경우가 많습니다. 특히 상관 서브쿼리(Correlated Subquery)는 성능이 매우 떨어질 수 있습니다.
- EXISTS vs. IN: 조건에 따라 IN 대신 EXISTS를 사용하는 것이 더 나을 수 있습니다. 특히 서브쿼리에서 IN은 전체 데이터를 조회하는 반면, EXISTS는 조건이 충족되면 바로 검색을 멈추기 때문에 더 빠르게 실행됩니다.
- 불필요한 열 선택 제거: SELECT *는 모든 열을 조회하므로, 필요한 열만 명시적으로 선택하는 것이 좋습니다. 필요한 열만 조회하면 I/O 성능이 향상됩니다.
3. 쿼리 실행 계획 확인
- EXPLAIN 명령어: EXPLAIN을 사용하여 쿼리 실행 계획을 확인하는 습관을 들이세요. 이를 통해 MySQL이 인덱스를 제대로 사용하고 있는지, 테이블 스캔이나 풀 스캔이 발생하는지 확인할 수 있습니다. EXPLAIN에서 중요하게 확인해야 할 값은 type, key, rows, Extra 등입니다.
- type: ALL (풀 스캔), range, ref, eq_ref 등의 값으로 인덱스 사용 여부와 효율을 나타냅니다.
- key: 실제 사용된 인덱스를 보여줍니다. 적절한 인덱스를 사용하고 있는지 확인할 수 있습니다.
4. 인덱스 조건 푸시다운 (Index Condition Pushdown, ICP)
MySQL 5.6 이후, ICP는 인덱스의 조건을 최적화하여 성능을 개선하는 기능입니다. 이는 인덱스 스캔 시 불필요한 데이터 로드를 최소화하고, 필요한 범위만 빠르게 찾는 데 도움을 줍니다. EXPLAIN에서 Extra 항목에 Using index condition이 나타나면 ICP가 사용된 것입니다.
5. 인덱스 힌트 사용
- 때로는 MySQL이 자동으로 선택한 인덱스가 최적이 아닐 수 있습니다. 이럴 때는 힌트를 사용하여 특정 인덱스를 강제로 사용하도록 할 수 있습니다. 예시로 USE INDEX, FORCE INDEX, IGNORE INDEX와 같은 힌트가 있습니다.
6. 데이터 정규화 및 비정규화
- 정규화: 중복 데이터를 줄이고 데이터 무결성을 유지하는 방식입니다. 하지만 정규화된 데이터가 과도하면 조인이 너무 많이 발생할 수 있어 성능이 저하될 수 있습니다.
- 비정규화: 읽기 성능이 중요한 경우, 데이터 중복을 허용하고 필요한 데이터를 한 번에 가져올 수 있도록 테이블을 비정규화할 수 있습니다.
7. 캐싱 활용
- 쿼리 캐싱: MySQL의 쿼리 캐시나 애플리케이션 레벨에서의 캐싱을 활용하면, 동일한 쿼리를 반복해서 실행할 때 성능을 크게 향상시킬 수 있습니다. 하지만 MySQL 8.0에서는 쿼리 캐시가 제거되었기 때문에 애플리케이션 레벨에서 캐싱을 고려하는 것이 좋습니다.
- 레디스(Redis) 또는 멤캐시드(Memcached): 자주 사용되는 데이터를 메모리 캐시로 저장하여 데이터베이스 조회를 줄일 수 있습니다.
8. 파티셔닝 및 샤딩
- 파티셔닝: 대용량 데이터를 여러 파티션으로 나누어 처리하면, 특정 범위의 데이터만 조회할 수 있어 성능을 크게 개선할 수 있습니다.
- 샤딩(Sharding): 데이터를 여러 서버에 분산하여 저장하고 처리하는 방식으로, 수평 확장성을 제공합니다. 대규모 데이터베이스 환경에서 매우 유용한 기술입니다.
9. 트랜잭션과 락 관리
- 트랜잭션 처리 최적화: 트랜잭션이 길어지면 성능이 저하될 수 있으므로, 가능한 한 트랜잭션의 범위를 좁히고 빠르게 처리하는 것이 중요합니다.
- 락(Lock) 관리: 테이블 락, 행 락이 지나치게 많이 발생하면 성능에 영향을 미칠 수 있습니다. 가능하면 행 수준의 락을 사용하는 것이 좋고, 필요한 경우 락 대기 시간을 모니터링하여 문제를 파악해야 합니다.
10. 인덱스 조정 및 유지 관리
- 인덱스 재구성: 데이터가 많이 변경될 경우, 인덱스가 단편화되어 성능 저하를 유발할 수 있습니다. 주기적으로 인덱스를 재구성하여 최적화 상태를 유지하는 것이 중요합니다.
- 불필요한 인덱스 제거: 너무 많은 인덱스가 있으면 INSERT, UPDATE, DELETE 성능이 저하됩니다. 자주 사용되지 않는 인덱스는 제거하는 것이 좋습니다.
11. 하드웨어 및 환경 최적화
- I/O 성능: SSD 같은 고속 스토리지를 사용하면 데이터베이스의 읽기/쓰기 성능을 크게 향상시킬 수 있습니다.
- 메모리 설정 조정: MySQL의 메모리 설정을 적절히 조정하여 더 많은 데이터를 메모리에 캐싱할 수 있도록 튜닝하는 것도 성능 향상에 큰 도움이 됩니다. innodb_buffer_pool_size 설정은 MySQL 성능에 중요한 영향을 미칩니다.
결론
SQL 성능 튜닝은 인덱스 활용 외에도 쿼리 작성 방식, 인덱스 설계, 데이터베이스 구조, 하드웨어 최적화 등 다양한 요소들이 상호작용하는 과정입니다. EXPLAIN 명령어를 활용하여 실행 계획을 분석하고, 문제를 발견한 후에 각 상황에 맞는 최적화 전략을 선택하는 것이 중요합니다.
'데이터베이스' 카테고리의 다른 글
| [MySQL] Index 인덱스란? (0) | 2024.12.30 |
|---|---|
| [MySQL] DBMS 압축 (0) | 2024.12.23 |
| MySQL InnoDB 트랜잭션과 락, 격리 수준 (1) | 2024.12.15 |
| InnoDB 스토리지 엔진 아키텍처, MYSQL 로그파일 (3) | 2024.12.10 |
| RealMySQL 4장 아키텍쳐 : MySQL 엔진에 대해 알아보자 (2) | 2024.12.06 |